


1. Johdanto
Scikit-learn (tai lyhyesti sklearn) on laaja ja helppokäyttöinen koneoppimisen kirjasto Python-kielelle [1]. Kirjasto tarjoaa valmiit työkalut lähes kaikkeen aiheeseen liittyvään. Kirjaston avulla on mahdollista (esi)käsitellä aineistoa sekä osittaa dataa opetus- ja validointidataksi ja se sisältää toteutukset tyypillisimmistä koneoppimisen algoritmeista. Kirjaston avulla on myös helppoa kattavasti testata kehitystyön tuloksena saatujen (opetettujen) mallien toimintaa sekä ottaa mallit käyttöön tuotannossa.
Scikit-learn perustuu avoimen lähdekoodiin ja BSD-tyyppiseen lisenssiin. Kirjaston käyttö on siten lähes sellaisenaan mahdollista myös kaupallisesti. On kuitenkin syytä huomata, että tyypillinen data-analytiikan ja koneoppimisen sovellus yhdistelee useita muitakin ohjelmakirjastoja (esim. numpy, pandas ja matplotlib), joiden lisenssit tulee tarkistaa erikseen.
Koska kyse on Python-ohjelmointikirjastosta, edellyttää Scikit-learnin käyttö tietenkin sekä Python-ohjelmointikielen että sopivan kehitysympäristön perusteiden hallintaa. Helppokäyttöisyydestään huolimatta Scikit-learn –kirjasto ei myöskään suoraan kerro, mihin tai miten eri koneoppimisen algoritmeja tulisi käyttää. Uuden käyttäjän näkökulmasta tyypillinen haaste on siten opiskella eri koneoppimisen algoritmeja ja niiden parametreja sekä kokeilla näiden soveltuvuutta erityyppisten sovellusaineistojen käsittelyyn.
Tässä dokumentin scikit-learn-kirjaston käyttöesimerkit on tehty käyttäen JupyterLab-työkirjaympäristöä [4]. Käytetty scikit-learn –versio on 0.24.2, mutta pienestä julkaisunumerostaan huolimatta, kirjasto on varsin vakaa.
Käytännössä kaikki kehitystyössä tarvittavat työkalut ja kirjastot (Python, scikit-learn ja muut keskeiset kirjastot sekä JupyterLab) — ja paljon muuta — on helpointa aluksi asentaa esim. Anaconda (Individual Edition) -kehitysympäristön mukana [5]. Anaconda on monipuolinen Python-ympäristöjen hallintaohjelma tai -ympäristö ja se on saatavilla Windows- ja Mac-ympäristöihin (ym.). Anacondan oletuksena paketoimien työkalujen (esim. JupyterLab) peruskäyttö on graafisen Anaconda Navigator -käyttöliittymän avulla erittäin suoraviivaista.
Scikit-learn-kirjasto on erittäin suosittu ja sen käyttöön ja opiskeluun löytyy paljon laadukasta, virallista dokumentaatiota, reseptityyppisiä esimerkkejä sekä kehittäjien ja käyttäjien kirjoittamia hyviä vinkkejä ja ohjeita [1,2,3]. Käytännössä hyviä vinkkejä ja koodiesimerkkejä voi löytää myös verkon yleiskäyttöisillä hakukoneilla (Google, Bing, DuckDuckGo, ym.), esim. avainsanalla scikit-learn tai sklearn.
2. Koneoppimisen perusidea
Tiedonlouhinnalla (data mining) tarkoitetaan prosessia, jossa tietystä ilmiöstä pyritään tekemään ennusteita, tai löytämään säännönmukaisuuksia tai poikkeavuuksia. Työn pohjana käytetään ilmiöstä kerättyä (määrällistä) aineistoa.
Koneoppiminen (machine learning) on puolestaan menetelmäperhe, jonka avulla määrämittaisesta datasta pyritään mekaanisesti, eri algoritmien avulla, opettamaan tai johtamaan samantyyppisen (uuden) aineiston havaintoyksiköitä luokittelevia tai kuvailevia malleja. Koneoppimisen avulla johdettuja malleja voidaan hyödyntää paitsi tiedonlouhinnassa, myös monissa muissa sovelluksissa.
Tyypillinen ohjatun koneoppimisen (supervised machine learning) pelkistetty prosessi on seuraava:
- Kohdesovelluksen ilmiöstä kerätään sopivalla otantamenetelmällä taulukkomuotoista aineistoa tai dataa, jossa kukin datarivi tai instanssi kuvaa yhden havaintoyksikön. Taulukon sarakkeet kuvailevat kunkin havaintoyksikön tietoja erilaisten kuvailevien ja luokittelevien attribuuttien avulla. Data ja sitä kautta sovellusilmiötä pyritään ymmärtämään visuaalisen analytiikan ja tilastotieteen perusmenetelmien avulla ja dataa hankitaan ja esikäsitellään (lisää) tarvittaessa.
- Aineisto jaetaan satunnaisesti kolmeen osaan, opetus-, validointi- ja (tuotannon) testidataksi, esim. osituksella 60%, 20% ja 20%. (Yksinkertaisemmissa tapauksissa, tai mikäli dataa on saatavilla niukalti, prosessi tehdään vain opetus- ja validointidata –jaottelun perusteella, esim. osituksella 70% ja 30%, ja varsinainen tuotantotestaus erikseen myöhemmin. Kaksiosaisen aineiston validointidataa kutsutaan usein lyhyesti myös testidataksi. Ilman oikeaa tuotannon testidataa, mallien toimivuudesta kehitysympäristön ulkopuolella ei kuitenkaan saada yhtä hyvää kuvaa.)
- Valitaan sopiva koneoppimisen algoritmi ja tämän parametrit. Kokeillaan opettaa algoritmi opetusdatalla. Tuloksena saatava opetettu malli testataan validointidatalla. Tuloksena nähdään, kuinka hyvin prosessin avulla opetettu malli suoriutuu luokittelutehtävästä validointidatan avulla. Prosessia toistetaan, kunnes ollaan tyytyväisiä mallin luokittelutarkkuuteen, ym.
- Lopuksi mallin toimivuutta koetellaan (tuotannon) testidatan avulla. Mikäli tulokset ovat riittävän hyviä, harkitaan mallin käyttöönottoa tuotantoprosessin laadunvarmistuksen mukaisella tavalla.
Ohjaamattoman oppimisen (unsupervised learning) sovelluksissa datarivejä tai instansseja ei ole opetusmielessä etukäteen luokiteltu, vaan kaikkia attribuutteja hyödynnetään instanssien kuvailuun. Tavoitteena on tällöin löytää aineistosta mielenkiintoisia rakenteita tai poikkeavia arvoja esim. klusteroinnin avulla: Rakenteita pyritään sitten selittämään heurististen sääntöjen ja tilastollisen testauksen keinoin.
Tapauksesta riippuen, em. prosessin yksityiskohdat vaihtelevat tietenkin suuresti, eikä abstraktien algoritmien sovellusten rajanveto eri tehtävien välillä ole täysin mustavalkoista. Esimerkiksi ohjattua oppimista voidaan käyttää myös aikasarjojen ennustamiseen ja klusterointialgoritmin ideaa luokittelutoteutuksen perustana.
3. Lyhyesti Python-ohjelmoinnista
Python on helppokäyttöinen, tulkattu, löyhästi tyypitetty, olio-ohjelmointia tukeva yleiskäyttöinen ohjelmointikieli, jota käytetään paljon esim. tieteellisessä laskennassa, erilaisissa serveritoteutuksissa sekä ad hoc -skripteissä [6]. Pythonille ominaista on mm. taulukoiden ja listojen ilmaisuvoimainen käyttö ohjelmoinnissa. Tämän ansiosta Python-ohjelmat ovat toisinaan ”paljon lyhyempiä ja helppolukuisempia” kuin esim. C++- tai Java-kieliset vastineensa.
Suosittuja ohjelmointikieliä kehitetään lisäämällä niihin ajan myötä uusia piirteitä ja poistamalla vanhoja. Python-kielen eri versioista on tätä kirjoittaessa saatavilla kaksi tärkeää päähaaraa, 2.7.x ja 3.x. Aloittelevan Python-kehittäjän näkökulmasta tuore 3.x -versio on yleensä parempi valinta (esim. 3.9).
Python-tulkkia (tai ydintä, ”kerneliä”) voidaan käyttää ohjelmointiympäristöissä myös interaktiivisesti. Tällöin Python-komentoja voidaan intuitiivisesti ajatellen syöttää myös yksitellen, sekä muokata ja tutkia sovelluksen ajonaikaista tilaa komentorivikehotteen tapaan interaktiivisesti. Työkirjaympäristöt kuten JupyerLab, perustuvat juuri tähän ideaan.
Python-ohjelmointiin on saatavilla runsaasti helppolukuisia ohjeita ja tutoriaaleja [7, 8].
Seuraava Python-kielinen ohjelmanpätkä esittelee ja kokeilee funktiota nimeltä print_next_odd_numbers. Ohjelma tulostaa tietyn lukumäärän annettua lukua seuraavia parittomia lukuja:
# Print n (number of) odd numbers which are greater or equal to f (the first number). def print_next_odd_numbers(f, n): # Initialize the printing variable x to start from the first number. x = f # If x is even (and hence not odd), add one to the first number. if x % 2 == 0: x = x + 1 # Print n (odd) numbers. for i in range(n): print(x) x = x + 2 # Finally, demonstrate using our function. print_next_odd_numbers(4, 3)
Ohjelman lähdekoodin voi tallettaa esim. odd.py -nimiseen tekstitiedostoon ja suorittaa komentoriviltä komennolla
python odd.py
Vaihtoehtoisesti, ohjelman voi suorittaa esim. graafisessa Spyder-kehitysympäristössä, tai koodin voi liittää ja suorittaa JupyterLab-työkirjan laskentasoluna. Jälkimmäisessä tapauksessa erillistä lähdekooditiedostoa ei muodostu, vaan koodi on osa työkirjan laajempaa sisältöä.
Niin tai näin, ohjelma tulostaa:
5
7
9
Kyse on nyt vain Python-koodin havainnollistuksesta, ilman sen kummempaa ”oikeaa” tehtävänasettelua. Saman ohjelmalogiikan voi usein toteuttaa usealla eri tavalla. Toteutustavat vaikuttavat esim. ohjelman suorituksen nopeuteen, muistinkulutukseen, koodin hallittavuuteen tai ohjelman suorituksen ymmärrettävyyteen ihmisten näkökulmasta.
Ohjelmalogiikan ymmärrettävyyttä voidaan merkittävästi parantaa lisäämällä koodin sekaan ihmisille tarkoitettuja kommentteja (#). Kommenttien tarkoitus on yleensä kuvata, mikä tietyn koodinpätkän idea tai tavoite on. Kommenttien merkitystä ei tule vähätellä: Ilman kommentteja (tai määrittelydokumentteja, testitapauksia, ym.) on hyvin vaikeaa ylipäänsä edes sanoa, toimiiko ohjelma ylipäänsä ”oikein”!
Riippumatta siitä, mitä suunnittelija haluaa, virheettömässä ajoympäristössä suoritettava tietokoneohjelma tekee siis aina täsmälleen sen, mitä ohjelmalogiikassa on käsketty. Tämä pätee tietyssä mielessä myös ympäristöään tarkkaileviin, datalähtöisiin tai jopa itse omaa ohjelmakoodiaan muokkaaviin tietokoneohjelmiin. Näiden toimintaa voi kuitenkin jopa ohjelmalogiikan suunnittelijan itsensä olla hyvin vaikea ennakoida, ainakin monimutkaisten syötteiden tapauksessa. (Filosofit — ja lainoppineet — voivat sitten pohtia, esim. missä vastuukysymyksissä kulkee rajaveto ohjelman tilaajan ja rahoittajan, ohjelmistosuunnittelijan, testaajan, dataympäristön ja ääritapauksessa jopa aikakehittyvän ohjelmakomponentin ”itsensä” välillä.)
Koska Python-kieli ja useat ohjelmointikirjastot on kirjoitettu ja dokumentoitu englanniksi, myös ohjelmien funktioiden ja muuttujien kuvaavat nimet (ym.) ja kommentit kirjoitetaan usein englanniksi.
Proseduraalisen ohjelmoinnin peruskäsitteitä ovat komentojen peräkkäis-, ehto- ja toistorakenne. Syöttö-, tulostus- ja muistinhallinta (ym.) hoidetaan apukirjastojen tarjoamien rakenteiden ja komentojen avulla. Yllä olevassa esimerkissä käytetään mm. muuttujien esittelyitä ja alustuksia, ehtolausetta, for-silmukkaa (tässä Pythonille tyypillinen listan [0, 1, 2, 3, …, n-1] alkiot iteroiva silmukka), laskutoimituksia ja vertailuoperaattoreita (jakojäännös, yhteenlasku, yhtäsuuruuden vertailu) sekä esitellään (def) ja kutsutaan funktiota tietyin parametrein. Ohjelmakoodia on lisäksi kommentoitu luonnollisella kielellä.
Huomaa, että Python käyttää ohjelmalohkojen tunnistamiseen sisennystä (eikä esim. aaltosulkuja kuten C-tyyppisissä ohjelmointikielissä). Tästä syystä Python-koodiesimerkkien leikkaa/liimaa-toimintojen kanssa on syytä olla tarkkana. Tekstieditorissa on usein turvallisinta käyttää sisentämiseen välilyöntimerkkejä tabulointimerkkien sijaan.
Koodaustaito on tietenkin tärkeää ohjelmistokehityksessä, mutta vain osa kokonaisuutta. Isommissa hankkeissa huomattava osa työtä on tehtävän ja sen hyväksyttävän ratkaisun selvittäminen, sovellusympäristöön soveltuvien teknologioiden sekä tietorakenteiden ja algoritmien valinta, näihin sopivien apukirjastojen valinta, ohjelmistoarkkitehtuurin suunnittelu, sekä ohjelmiston toteutuksen, testauksen, jakelun ja ylläpidon resurssoinnin ja laadun asianmukainen varmistaminen, asiakkaan ja eri alojen asiantuntijoiden kanssa.
4. JupyterLab-ympäristön peruskäyttö
JupyterLab on interaktiivisen laskennan ympäristö, jonka avulla on mahdollista työskennellä esim. työkirjapohjaisten (workbook) Python-sovellusten kanssa.
Kun Anaconda on asennettu, JupyterLab-ympäristön käynnistäminen onnistuu esim. Anaconda Navigator –paletin JupyterLab-ikonin avulla (Launch):
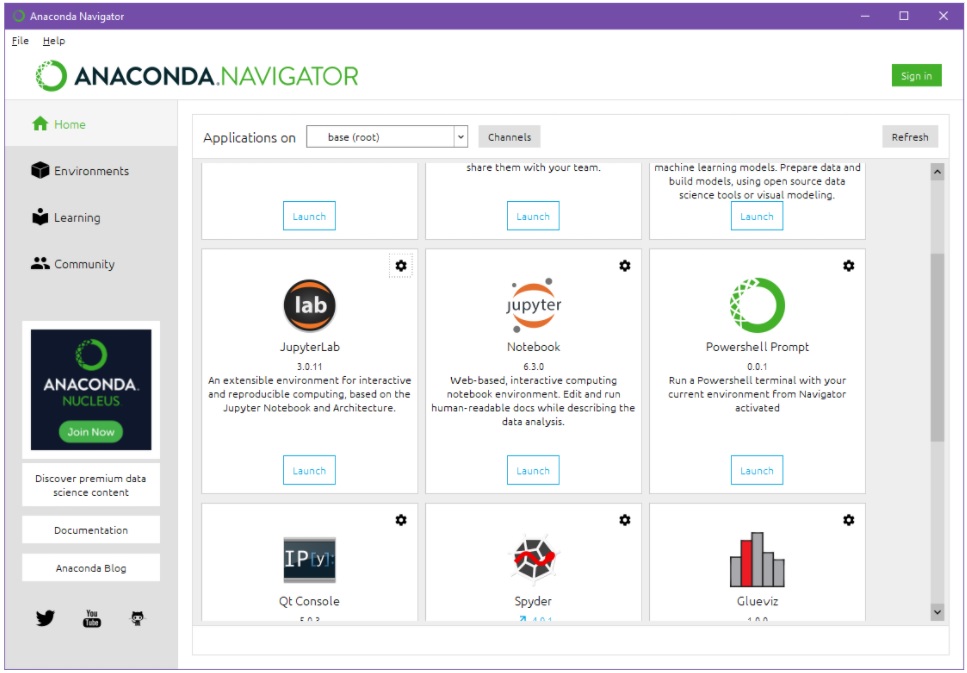
Huomaa, että Anacondan perusfilosofian mukaisesti, JupyterLab käynnistetään valittuun Python-ympäristöön (tms.), edellä oletuksena määriteltyyn base-ympäristöön. Kehittäjän on kuitenkin myös mahdollista määritellä Anaconda-ympäristöjä itse. Tämä on tärkeää, koska kaikki kehitystyössä tarpeelliset, lukuisat (Python-)kirjastot eivät aina toimi yhteen esim. uusimpien versioiden osalta. Anacondan avulla voidaan määritellä ympäristöjä, joissa käytössä on jokin tietty kombinaatio työkalujen eri versioita — siten, että tästä aiheutuva monimutkaisuus pysyy hallittavissa Anacondan sisällä.
Kun JupyterLab on käynnistynyt, tuloksena saadaan Python-kerneliä (esim. versio 3.9) ja omalla koneella ajettavaa, oletuksena omalle koneelle rajattua verkkopalvelinta (ym.) suorittava taustaprosessi sekä selaimessa toimiva JupyterLab-käyttöliittymä:
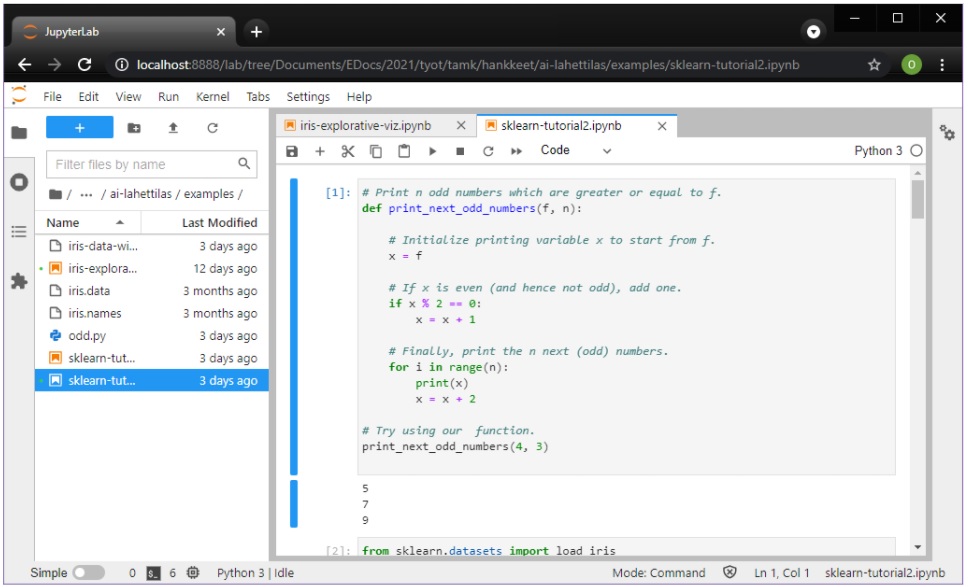
Selainpohjaisuudestaan huolimatta, työkirjoja käytännössä luodaan, hallitaan ja muokataan periaatteessa kuten mitä tahansa dokumentteja, ja tiedostot pysyvät oletuksena vain omalla tietokoneella. Työkirjan käyttö onnistuu joko menujen tai näppäinkomentojen avulla.
JupyterLab-työkirja koostuu koodi- ja kommenttisoluista. Koodisolut sisältävät mielivaltaista Python-koodia, joiden suorittaminen muuttaa Python-kernelin tilaa ja saattaa tuottaa esim. tulosteen tai kuvan koodisolun jälkeen. Kommenttisolut puolestaan sisältävät Markdown-koodia, jonka avulla työkirjaan on mahdollista kirjoittaa esim. otsikoita, leipätekstiä, linkkejä (esim. # Otsikko tai **lihavointi**) sekä LaTex-tyyppisiä matemaattisia kaavoja (esim. $f(x)=x^2$).
Huomaa, että solujen ajojärjestys ja siten kernelin tila määräytyy käyttäjän toimenpiteiden perusteella — mikä mahdollistaa koodisolujen suorittamisen työkirjasta muussakin kuin peräkkäisjärjestyksessä (vrt. solujen vasemmalla puolella olevien hakasulkeiden välissä oleva numerointi). Työkirjaa vastaavan kernelin voi kuitenkin aina halutessaan käynnistää uudelleen ja suorittaa kaikki solut peräkkäisjärjestyksessä ylhäältä alas.
5. Scikit-learn –kirjaston peruskäyttö
Tarkastellaan seuraavaksi yksinkertaisen koneoppisovelluksen pelkistettyä rakennetta scikit-learn –kirjaston avulla.
Valitaan aineistoksi tuttu Iiris dataset [9]. Iiris-aineistossa on kuvattu 150×5 –kokoiseen taulukkoon 150 eri mitatun yksittäisen kukkasen (tässä datarivi tai instanssi) verho- ja terälehtien pituudet (sepal=verholehti, petal=terälehti) sekä asiantuntijan tunnistama kukkalaji (class). Tässä tyypillisen kehitystehtävän tavoite on käyttää ensimmäisiä kuvailevia attribuutteja viidennen luokka-attribuutin ennustamiseen.
Vaihe 1: Ensimmäinen tehtävä on datan lataaminen kirjastoon sopivassa muodossa.
Scikit-learn tarjoaa opiskelumielessä mahdollisuuden ladata koneoppimisen klassisia aineistoja, mukaan lukien iiris-aineiston, suoraan scikit-learn –kirjaston funktiona:
from sklearn.datasets import load_iris iris = load_iris() # Load the iris dataset. print(iris)
Tuloksena saadaan scikit-learn-kirjaston dictionary-tyyppiä muistuttava tietorakenne Bunch, joka kokoaa yhteen aineiston eri piirteet: Instanssien kuvailevat attribuutit taulukkona, luokittelevan attribuutin arvot vektorina sekä kuvailevien attribuuttien nimet ja luokkien nimet (kentät data, target, feature_names ja target_names).
Edellinen toimii siis vain klassisten esimerkkiaineistojen tapauksessa: Käytännössä oma sovelluskohtainen aineisto on tietenkin aina omanlaistaan ja se halutaan usein ladata esim. csv-tiedostosta.
Ladataankin seuraavaksi esimerkin vuoksi iiris-data itse käsitellystä tekstitiedostosta:
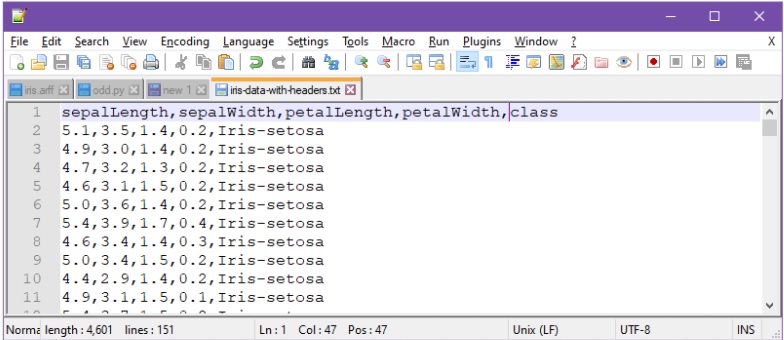
Yllä csv-tiedoston alkuun on lisätty attribuuttien nimet metatietoina. (Huomaa, että Pandas-kirjasto olettaa, että attribuuttien esiintyvät csv-tiedostossa ilman tyhjämerkkejä — tai sitten pitää esim. varautua siihen, että attribuuttien nimien alussa on koodeissa väliyöntejä.)
Csv-tiedoston lataamiseen voidaan nyt käyttää esim. Pandas-kirjastoa apuna:
import pandas as pd
df = pd.read_csv(”iris-data-with-headers.txt”, sep=”,”)
df[:5] # Show first five lines.
On tyypillistä, että omassa koodissa hyödynnetään useita apukirjastoja.
Yllä oleva ohjelma lataa csv-tiedoston Pandas-kirjaston DataFrame-tyyppisenä objektina ja tulostaa aineiston viisi ensimmäistä riviä tai instanssia:
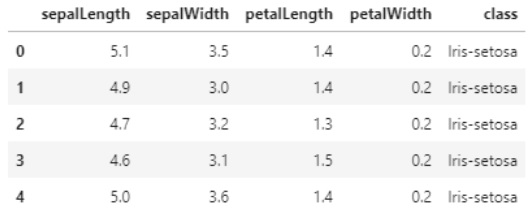
Ikävä kyllä, eri kirjastojen tietorakenteet on kehitetty eri tarkoituksia silmällä pitäen, eivät ne siten ole täysin yhteensopivia. Kootaan seuraavassa Pandas-kirjaston lataamat DataFrame-muotoiset tiedot vastaavantyyppiseen Bunch-tietorakenteeseen:
from sklearn import preprocessing from sklearn.utils import Bunch # Get the four first columns as features names and data features. feature_names = list(df.columns) feature_names = feature_names[0:4] data = df.to_numpy() data = data[0:,0:4] # Convert target classes from strings into numerical values, using scikit-learn preprocessing utilities. target = list(df["class"]) le = preprocessing.LabelEncoder() le.fit(target) target = le.transform(target) # Compile Bunch object from the data. iris = Bunch(data=data, target=target, feature_names=feature_names, target_names=le.classes_ )
Käytännössä tuloksena saadaan suunnilleen vastaava rakenne, kuin mitä komento load_iris() olisi tuottanut — mutta nyt data on itse ladattu ja kasattu csv-tiedostosta. Huomaa, että luokitteleva attribuutti muunnettiin edellä numeeriseen muotoon: Kun opetettu koneoppimisen malli tulostaa 0, tarkoittaa se intuitiivisesti siis Iris-setosa –luokkaa, jne.
Bunch-rakenteen käyttö ei toki tarkkaan ottaen ole välttämätöntä, mutta Pythonissa on yleensä kätevää niputtaa yhteenkuuluvat tiedot yhteen ja samaan tietorakenteeseen. Käytännössä myös monet ohjelmoinnin aloitusoppaat käsittelevät komennolla load_iris() (ym.) ladattuja aineistoja, eli kolmansien osapuolten esimerkkien seuraaminen on alussa paljon helpompaa jos ja kun omakin aineisto on Bunch-rakenteen mukaisessa muodossa.
Vaihe 2: Alustavien kokeiluiden hengessä, jaetaan data kahteen koriin, 70% opetusdataksi ja 30% validointidataksi (tai kehitysvaiheen testidataksi):
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3)
Opetus- ja testidatan rivien lukumääriä voidaan nyt havainnollistaa pylväsdiagrammeina (tämäkään ei ole välttämätöntä, mutta opintojen alkumetreillä hyvä todeta):
import numpy as np import matplotlib.pyplot as plt # Group data. bundle=[('training data',len(X_train)),('test data',len(X_test))] labels, ys = zip(*bundle) xs = np.arange(len(labels)) # Plot as bars. plt.bar(xs, ys, 1, color=('green','black'), align='center') plt.xticks(xs, labels) plt.title('Number of training and validation instances') plt.show()
Aineiston 105 (satunnaista) riviä tai instanssia tuli siis valituksi opetusdataksi ja loput 45 testidataksi:
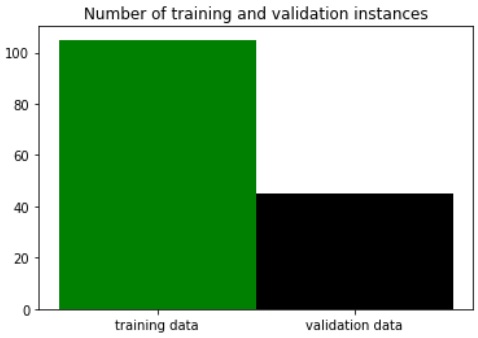
Vaihe 3: Opetusdatan avulla voidaan sitten opettaa esim. naiivi bayesilainen (Naive Bayes, NB) luokittelumalli:
from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() gnb.fit(X_train, y_train)
Klassisen koneoppimisen käyttötapauksessa Naive Bayes –algoritmi tuottaa yleensä tulosten perustason, jonka perusteella tuloksia pyritään parantamaan. Luokitustuloksia pyritään parantamaan eri algoritmeja kokeilemalla, sopivilla parametrien valinnoilla sekä keräämällä tai oivaltavasti esikäsittelemällä (lisää) aineistoa.
Muut scikit-learn –oppimisalgoritmit toimivat täsmälleen samalla rajapinnalla (fit, predict, ym.). Siten ne eroavat toisistaan vain parametrien, dataan liittyvien olettamusten, sekä tietenkin toteutuksensa ja valmiiden mallien osalta (ks. [10]). Toisin sanoen, esim. päätöspuiden, neuroverkkojen tai tukivektorikoneiden avulla tapahtuva mallinnus tapahtuu vastaavasti, edellä yksinkertaisimmillaan korvaamalla koodin GaussianNB()-termi (ym.) esim. jollakin seuraavista: DecisionTreeClassifier(), MLPClassifier() tai SVC().
Kuten jo todettua, monimutkaisemmissa tapauksissa haasteeksi muodostuu lähinnä aineiston esikäsittely ja opetusalgoritmien parametrien valinta.
Vaihe 4: Kokeillaan alustavasti, kuinka hyvin edellä opetettu malli toimii.
Luokitellaan mallin avulla testiaineisto, tuloksena y_pred-taulukko ja tarkastellaan ensin tuloksen tarkkuutta:
y_pred = gnb.predict(X_test) print(gnb.score(X_test, y_test))
Nyt tuloksena saadaan esim. 0.93 eli 93%, mikä on hyvä tarkkuus — ja erityisesti kertoo iiris-aineiston helppoudesta. (Huomaa, että tarkka tulos riippuu satunnaisesti valituista opetus- ja testidatoista.)
Tarkastellaan seuraavaksi virheitä, joita opetettu malli nyt tekee:
from sklearn.metrics import confusion_matrix import seaborn as sns # Compute confusion matrix. cm = confusion_matrix(y_test, y_pred) # Plot the confusion matrix using Pandas and Seaborn. cm_df = pd.DataFrame(cm,iris.target_names,iris.target_names) plt.figure(figsize=(10,6)) plt.title('Gaussian Naive Bayes Confusion Matrix') sns.heatmap(cm_df, annot=True) plt.show()
Koodinpätkän tuloksena saadaan havainnollinen esitys sekaannusmatriisista (confusion matrix):
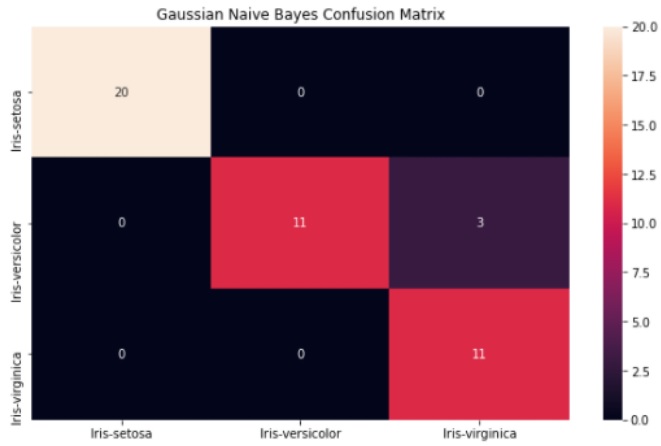
Sekaannusmatriisista havaitaan, millaisia luokitteluvirheitä malli teki: Esim. toisella rivillä, kun mallin olisi pitänyt tulostaa 14 kertaa Iris-versicolor, se erehtyi kolme kertaa tulostamaan Iris-virginica.
Hieman samantyyppistä tietoa mallin toimivuudesta antaa myös luokitteluraportti:
# Show basic information retrieval results. # Precision: The fraction of relevant instances among the retrieved instances. # Recall: The fraction of relevant instances that were retrieved. # C.f. https://en.wikipedia.org/wiki/Precision_and_recall from sklearn.metrics import classification_report print(classification_report(y_test, y_pred, target_names=iris.target_names))
Nyt tuloksena saadaan mallin toimivuuden tunnuslukuja luokkien suhteen:
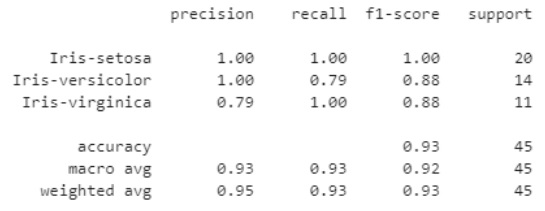
Yksittäisen testin perusteella ei kuitenkaan voida sanoa mallin toimivuudesta kovin kauaskantoisia linjauksia: On tietenkin mahdollista, että puhtaalla sattumalla on suuri rooli, kun dataa jaetaan sattumanvaraisesti opetus- ja validointiosajoukkoihin.
Opetusdatan ja algoritmien parametrien valinnan perustavoite on johtaa tai opettaa malli, joka intuitiivisesti sanottuna osaa yleistää oppimaansa. Hyvä malli osaa siten esim. paitsi luokitella opetusdatansa instansseja, osaa se myös luokitella validointi- ja testidatan instansseja. Erityisesti, monimutkaisten algoritmien mallien tapauksessa voi käydä niin, että malli ylioppii ”muistamaan ulkoa” opetusdatan (overfitting) — muttei sitten toimikaan validointidatan saati tuotantovaiheen testidatan kanssa.
Ylioppimista voidaan välttää opetusdatajoukkoa pienentämällä sekä sopivien parametrien valinnalla. Esimerkiksi päätöspuun tai neuroverkon solmujen lukumäärä vaikuttaa siihen, kuinka monimutkaisia oppimistuloksia (tai matemaattisia funktioita) niiden avulla voidaan mallintaa.
Kaikki oppimisalgoritmit eivät toimi (hyvin) kaikentyyppisillä (kuvailevilla) attribuuteilla. Sopivien attribuuttien laatu tulee tarkistaa algoritmien ohjeista. Usein kuvailevien attribuuttien tulisi olla numeerisia ja vähintään järjestysasteikollisia muuttujia. Joidenkin algoritmien (esim. neuroverkot) tapauksessa attribuuttien arvot tulisi lisäksi vielä normalisoida, eli skaalata sopivasti.
Vaihe 5: Olettaen, että aineisto otanta on onnistunut, edellisen kaltaista yksittäisten validointitulosten sattumanvaraisuutta voidaan pienentää tekemällä aineistoon systemaattisesti monta opetus-validointidata -ositusta. Seuraavassa lasketaan kymmenen kertaa 9:1 ositus opetus- ja validointidataan, opetetaan ja testataan malli kullekin ositukselle ,ja tarkastellaan tuloksia:
# Perform 10-fold cross-validation with the model: from sklearn.model_selection import cross_val_score scores = cross_val_score(GaussianNB(), iris.data, iris.target, cv=10) print( scores.mean(), "= mean of", scores)
Tulosteena saadaan:
0.9533333333333334 = mean of [0.93333333 0.93333333 1. 0.93333333 0.93333333 0.93333333 0.86666667 1. 1. 1.]
Tuloksesta nähdään, että kymmenen ajon tapauksessa, yksittäisen ajon tarkkuus vaihtelee nyt välillä 87% – 100%. Tältä pohjalta voidaan jo hieman uskottavammin sanoa, että ko. datan ja oletusparametrien kanssa, GaussianNB()-algoritmi tuottaa keskimäärin n. 95% luokitustarkkuuden.
Vaihe 6: Opetusalgoritmien parametrien merkityksen opiskelu ja sopivien parametriarvojen valinta tuottavat käytännössä usein päänvaivaa. Jos ja kun suoritustehoa tietokoneessa riittää, on parametreja mahdollista hakea onneksi myös brute force –tekniikalla. Seuraavassa yritetään esimerkinomaisesti löytää sopivia parametreja KNeighborsClassifier()-algoritmille yksittäisen X_train, y_train -otoksen varassa:
from sklearn.model_selection import GridSearchCV from sklearn import neighbors # Rework test and train data. X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3) # Combinations to try out: parameters = [{ 'n_neighbors': range(1,15,2), 'weights': ['uniform', 'distance'], 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'] }] # Introduce and train the classifier with all the above parameter combinations. clf = GridSearchCV(neighbors.KNeighborsClassifier(), parameters) clf.fit(X_train, y_train) # Print best params found and related score. print("Best combination of parameters found: ", clf.best_params_) print("Score", clf.score(X_test, y_test))
Tulosteena saadaan nyt:
Best combination of parameters found: {'algorithm': 'auto', 'n_neighbors': 3, 'weights': 'uniform'} Score 0.9777777777777777
Erinomaiset tulokset kertovat taas iiris-aineiston helppoudesta.
Käytännössä ”kaikkien” parametrikombinaatioiden hakeminen ei tietenkään ole mahdollista, saati järkevää. Tyypillinen strategia on hakea hyviä parametreja iteratiivisesti esim. hakemalla aluksi heuristisen arvion perusteella summittaisia parametriarvoja, joita sitten tutkitaan tarkemmin puolitushaulla.
Vastaavasti on toki mahdollista hakea myös dataan sopivia koneoppimisen algoritmeja, ym. Parametrien optimoinnissa on kuitenkin syytä pitää varansa, ettei mallia ja sen parametreja valita vain validointidatalle sopiviksi — kuten todettua, mallien tulisi tietenkin yleisessä tapauksessa toimia myös lopullisen tuotannon testidatan kanssa.
Vaihe 7: Kun sopiva malli on saatu aikaiseksi, on sen käsittely ja käyttö Python-ohjelmassa helppoa:
# Classify unseen instance with ad hoc data (not really measured from any flower): unseen_instance = [[3,2,2,3]] result = clf.predict(unseen_instance)[0] print(result)
Luokituksen tuloksena saadaan nyt Iris-versicolor eli:
1
Lopullisen, koneoppimista hyödyntävän sovelluksen toteuttaminen vaatii tietenkin paljon muutakin. Esimerkiksi valmiita malleja kannattaa tallettaa tiedostoihin ja sovelluksissa ja siten datassa usein tapahtuvan aikakehityksen takia opetettuja malleja voi olla tarpeen tietyin väliajoin pyrkiä korvaamaan uudella datalla opetetuilla, uuden validointiaineiston kanssa paremmin suoriutuvilla malleilla, jne.
6. Lopuksi
Tulosten hyväksyttävyyttä arvioitaessa kannattaa pitää mielessä, että koneoppimisen mallit toimivat pääsääntöisesti vain tietyllä tilastollisella tarkkuudella. Hyväkin ennuste- tai luokittelumalli voi esimerkiksi tuhannen ajon tapauksessa antaa keskimäärin yhdeksässä tapauksessa kymmenestä oikean tuloksen — mutta siten yhdessä tapauksessa kymmenestä (täysin) väärän.
Erityyppisiä virheitä sattuu siis väistämättä. Koneoppimisen virheiden vaikutusten minimointi kriittisissä sovelluksissa on siten tärkeää, aivan kuten ihmistenkin tekemien virheiden vaikutusten minimointi on.
Lähteitä
[1] Scikit-learn: Machine learning in Python. Scikit-learn developers. Saatavilla https://scikit-learn.org/stable/
[2] User guide: Contents — scikit-learn documentation. Scikit-learn developers. Saatavilla https://scikit-learn.org/stable/user_guide.html
[3] Examples — scikit-learn documentation. Scikit-learn developers. Saatavilla https://scikit-learn.org/stable/auto_examples/index.html
[4] Project Jupyter | Home. Project Jupyter. Saatavilla https://jupyter.org/
[5] Anaconda | Individual Edition. Anaconda Inc. Saatavilla https://www.anaconda.com/products/individual
[6] Welcome to Python.org. Python Software Foundation. Saatavilla https://www.python.org/
[7] BeginnersGuide – Python Wiki. Welcome to Python.org. Python Software Foundation. Saatavilla https://wiki.python.org/moin/BeginnersGuide
[8] The Python Tutorial — Python 3.x. Python Software Foundation. Saatavilla https://docs.python.org/3/tutorial/index.html
[9] Iris flower data set. Wikipedia. Saatavilla https://en.wikipedia.org/wiki/Iris_flower_data_set
[10] 1. Supervised learning — scikit-learn documentation. Scikit-learn developers. Saatavilla https://scikit-learn.org/stable/supervised_learning.html
Kommentit