

1. Johdanto
Weka on Java-pohjainen, Windows- ja Mac-työpöytäympäristöihin (ym.) asennettava työkaluohjelma, jonka avulla on mahdollista kohtuullisen helposti tehdä tiedonlouhinnan ja koneoppimisen kokeiluita [1]. Wekan asennus edellyttää, että tietokoneella on Java jo valmiiksi asennettuna, tai sitten Wekasta pitää asentaa itsenäinen, Java-virtuaalikoneen sisältävä ohjelmaversio.
Weka sisältää valmiiksi ohjelmoituna tyypillisimmät koneoppimisen opetusalgoritmit, opetettujen mallien testaustyökalut, attribuuttien valintatyökalut ja visualisointien toteutukset, sekä tarjoaa näiden hyödyntämiseen johdonmukaisen graafisen käyttöliittymän.
Yksinkertaisten kokeiluiden tekeminen ei siten vaadi ohjelmointitaitoa, mutta edellyttää asianmukaisesti esikäsiteltyä dataa sekä erilaisten koneoppimisen algoritmien mallien ja tilastollisen testaamisen menetelmien peruskäytön ymmärtämistä [2]. Erityisesti: Weka helpottaa suuresti kokeiluiden aloittamista, mutta ei suoraan kerro, mihin tai miten eri algoritmeja tulisi käyttää. Uuden käyttäjän näkökulmasta tyypillinen haaste on siten opiskella eri koneoppimisen algoritmeja, niiden parametreja ja soveltuvuutta erityyppisten sovellusaineistojen käsittelyyn — mutta Weka tarjoaa tähän opiskeluun mainiot kokeilevat puitteet.
Wekan käyttö osana monimutkaisempia koneoppimisen sovelluksia puolestaan edellyttää lisäksi myös mm. ohjelmistokehityksen ja Java-teknologian hallintaa.
Weka on saatavilla GNU General Public –lisenssin mukaan (GPL 2.0, Weka 3.6) ja (GPL 3.0, Weka > 3.7.5) [3]. Weka-ohjelmistokomponenttien jakaminen osana kaupallista käyttöä edellyttää joko GPL-lisenssiin sitoutumista, tai erillisten lisenssien ostamista (yksittäisiltä lähdekirjastotoimittajilta).
Weka-ympäristö tarjoaa erilaisia sovelluksia koneoppimisen kokeiluiden tekemiseen:
- Explorer (aineiston tutkiminen ja erilaisten luokittelu- ja klusterointikokeiluiden tekeminen);
- Experimenter (koneoppimiskokeiluiden määrittely ja tallettaminen useita ajoja niiden suorituskyvyn vertailua silmällä pitäen);
- KnowledgeFlow (koneoppimisen datalähtöisten käsittelyputkien avulla tehtävät kokeilut);
- Simple CLI (komentorivipohjainen pääsy Weka-toimintoihin); ja
- Workbench (em. Weka-sovellusten yhteiskäyttö integroidun käyttöliittymän avulla).
Wekan keskeisiin toimintoihin on mahdollista päästä kirjastotasolla käsiksi myös Java-ohjelmarajapintojen avulla, so. ilman graafista käyttöliittymää.
Tässä aloitusohjeessa esitellään lyhyesti vain Explorer-sovelluksen peruskäyttöä: Explorer –sovelluksen avulla on mahdollista ladata koneoppimisen (suurimmalta osin valmiiksi esikäsiteltyjä) aineistoja, suorittaa koneoppimisen algoritmien opetusajoja erilaisten parametrien avulla, testata mallien toimivuutta validointidatan avulla sekä tarkastella ja visualisoida testien tuloksia. (Katso lisätietoja Weka-dokumentaatiosta [4] tai esim. blogilähteestä [5].
Saatavilla on myös mainiota koneoppimisen ja tiedonlouhinnan kirjallisuutta, joka osaltaan sivuaa Wekan käyttöä; ks. erit. [7]. Myös itse Weka-ympäristön opiskeluun ja käyttöön on saatavilla runsaasti hyvälaatuista kurssi- ja itseopiskelumateriaalia [4, 13]. Opetusmateriaali sisältää ohjedokumenttien ja esimerkkiaineistojen lisäksi kymmeniä lyhyitä ja selkeitä, englanninkielistä itseopiskeluvideota, joiden avulla Wekaa on mahdollista kokeilla esimerkkien avulla.
2. Tiedonlouhinnan ja koneoppimisen perusidea
Tiedonlouhinnalla (data mining) tarkoitetaan prosessia, jossa tietystä ilmiöstä pyritään tekemään ennusteita, tai löytämään säännönmukaisuuksia tai poikkeavuuksia. Työn pohjana käytetään ilmiöstä kerättyä (määrällistä) aineistoa.
Koneoppiminen (machine learning) on puolestaan menetelmäperhe, jonka avulla määrämittaisesta datasta pyritään mekaanisesti, eri algoritmien avulla, opettamaan tai johtamaan samantyyppisen (uuden) aineiston havaintoyksiköitä luokittelevia tai kuvailevia malleja. Koneoppimisen avulla johdettuja malleja voidaan hyödyntää paitsi tiedonlouhinnassa, myös monissa muissa sovelluksissa.
Tyypillinen ohjatun koneoppimisen (supervised machine learning) pelkistetty prosessi on seuraava:
- Kohdesovelluksen ilmiöstä kerätään sopivalla otantamenetelmällä taulukkomuotoista aineistoa tai dataa, jossa kukin datarivi tai instanssi kuvaa yhden havaintoyksikön. Taulukon sarakkeet kuvailevat kunkin havaintoyksikön tietoja erilaisten kuvailevien ja luokittelevien attribuuttien avulla. Data ja sitä kautta sovellusilmiötä pyritään ymmärtämään visuaalisen analytiikan ja tilastotieteen perusmenetelmien avulla ja dataa hankitaan ja esikäsitellään (lisää) tarvittaessa.
- Aineisto jaetaan satunnaisesti kolmeen osaan, opetus-, validointi- ja (tuotannon) testidataksi, esim. osituksella 60%, 20% ja 20%. (Yksinkertaisemmissa tapauksissa, tai mikäli dataa on saatavilla niukalti, prosessi tehdään vain opetus- ja validointidata –jaottelun perusteella, esim. osituksella 70% ja 30%, ja varsinainen tuotantotestaus erikseen myöhemmin. Kaksiosaisen aineiston validointidataa kutsutaan usein lyhyesti myös testidataksi. Ilman oikeaa tuotannon testidataa, mallien toimivuudesta kehitysympäristön ulkopuolella ei kuitenkaan saada yhtä hyvää kuvaa.)
- Valitaan sopiva koneoppimisen algoritmi ja tämän parametrit. Kokeillaan opettaa algoritmi opetusdatalla. Tuloksena saatava opetettu malli testataan validointidatalla. Tuloksena nähdään, kuinka hyvin prosessin avulla opetettu malli suoriutuu luokittelutehtävästä validointidatan avulla. Prosessia toistetaan, kunnes ollaan tyytyväisiä mallin luokittelutarkkuuteen, ym.
- Lopuksi mallin toimivuutta koetellaan (tuotannon) testidatan avulla. Mikäli tulokset ovat riittävän hyviä, harkitaan mallin käyttöönottoa tuotantoprosessin laadunvarmistuksen mukaisella tavalla.
Ohjaamattoman oppimisen (unsupervised learning) sovelluksissa datarivejä tai instansseja ei ole opetusmielessä etukäteen luokiteltu, vaan kaikkia attribuutteja hyödynnetään instanssien kuvailuun. Tavoitteena on tällöin löytää aineistosta mielenkiintoisia rakenteita tai poikkeavia arvoja esim. klusteroinnin avulla: Rakenteita pyritään sitten selittämään heurististen sääntöjen ja tilastollisen testauksen keinoin.
Tapauksesta riippuen, em. prosessin yksityiskohdat vaihtelevat tietenkin suuresti, eikä abstraktien algoritmien sovellusten rajanveto eri tehtävien välillä ole täysin mustavalkoista. Esimerkiksi ohjattua oppimista voidaan käyttää myös aikasarjojen ennustamiseen ja klusterointialgoritmin ideaa luokittelutoteutuksen perustana.
Weka tarjoaa välineitä kaikkien edellä mainitun prosessin vaiheiden tueksi.
3. Weka Explorer –sovelluksen peruskäyttö
Weka Explorer –sovelluksen avulla on mahdollista tutkia dataa sekä kokeilla ja analysoida erilaisten koneoppimisalgoritmien toimintaa.
Sovelluksen pelkistetty työkulku on lyhyesti kuvattu alla. Huomaa, että Wekan toteutus ja käyttöliittymä saattavat kehittyä uusien ohjelmaversioiden myötä, mistä syystä tuorein Weka-versio saattaa näyttää hieman erilaiselta. Tämä dokumentin esimerkit on tehty versiolla 3.8.4.
Vaihe 1: Työn ensimmäisessä, alustavassa vaiheessa valmistellaan lähdedata sopivassa formaatissa (oletuksena arff–formaatti [6]).
Tässä esimerkkinä klassinen ja helppo iiris-aineisto, ladattuna tekstieditoriin [12]:
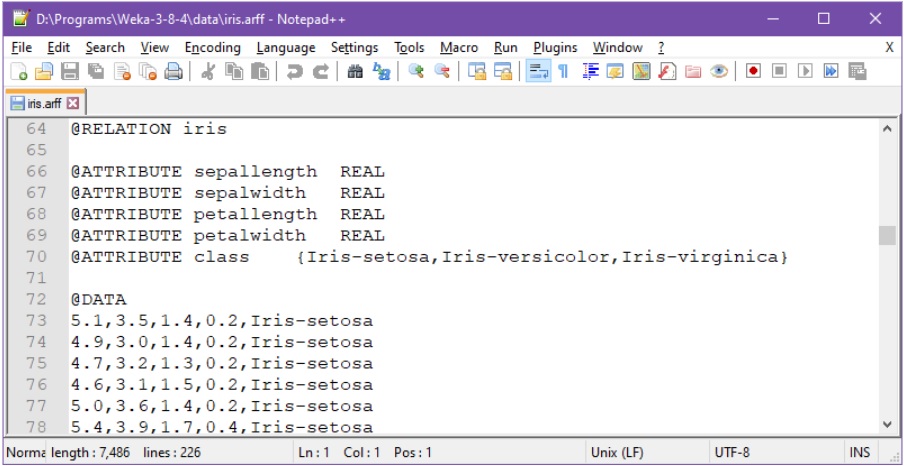
Ensimmäisellä rivillä attribuuttien nimet sepalLengthCm, sepalWidthCm, petalLengthCm, petalWidthCm ja class, pilkulla eroteltuna. Toiselta riviltä alkaen kukin yksittäinen datarivi sisältää pilkulla erotettuna neljän ensimmäisen kuvailevan attribuutin numeerista tietoa, esim. toisella rivillä 5.1,3.5,1.4,0.2. Kunkin datarivin lopussa on vielä luokitteleva merkkijono, esim. toisen rivin lopussa teksti Iris-setosa.)
Arff-muotoinen Iiris-aineisto tulee mm. Weka-asennuksen mukana ja löytyy data-hakemistosta. Aineistossa on kuvattu 150×5 –kokoiseen taulukkoon 150 eri mitatun yksittäisen kukkasen (tässä datarivi tai instanssi) verho- ja terälehtien pituudet (sepal=verholehti, petal=terälehti) sekä asiantuntijan tunnistama kukkalaji (class). Tässä tyypillisen kehitystehtävän tavoite on käyttää ensimmäisiä neljää kuvailevia attribuutteja viidennen luokka-attribuutin ennustamiseen.
Arff-muotoisen tiedoston alussa on lisäksi kuvattu attribuuttien metatietoja ja se voi myös sisältää ihmisille tarkoitettuja kommentteja (%).
Wekaan voi arff-formaatin sijaan toki ladata dataa myös muun tyyppisistä datatiedostoista, esimerkiksi tutuista csv-tiedostoista:
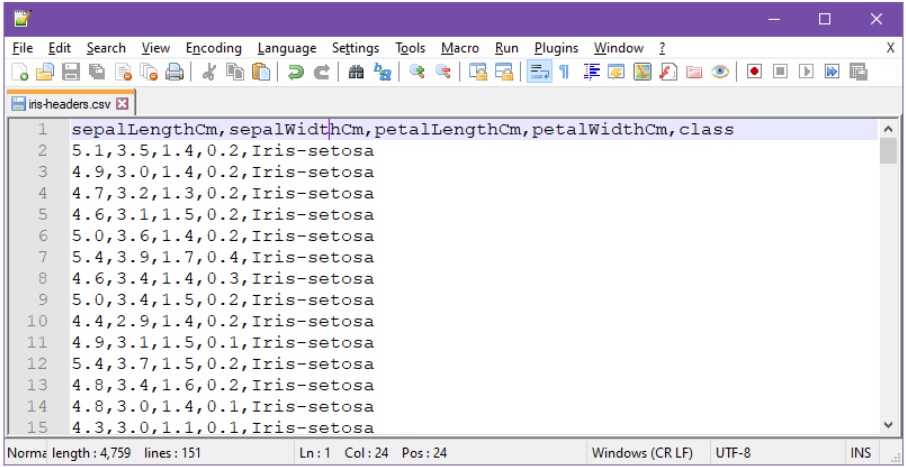
Csv-tiedostojen tapauksessa, ensimmäisen rivin tulee nimetä attribuutit, ilman tyhjämerkkejä erotinmerkkien välillä (yllä pilkku).
Vaihe 2: Käynnistetään Weka GUI Chooser:
Weka GUI Chooser tarjoaa sovelluspaletin ohella myös pääsyn mm. Wekan kolmannen osapuolten lisäosien hallintaan ja muihin yksittäisten Weka-sovellusten taustalla tarvittaviin toimintoihin (ks. Tools-menu).
Vaihe 3: Käynnistetään paletista (Weka) Explorer:
Vaihe 4: Ladataan sopivasti käsitelty aineisto Weka Explorer –sovellukseen (Open file…). Seuraavassa ladataan edellä kuvattu iris.arff (tai iris.csv tms.):
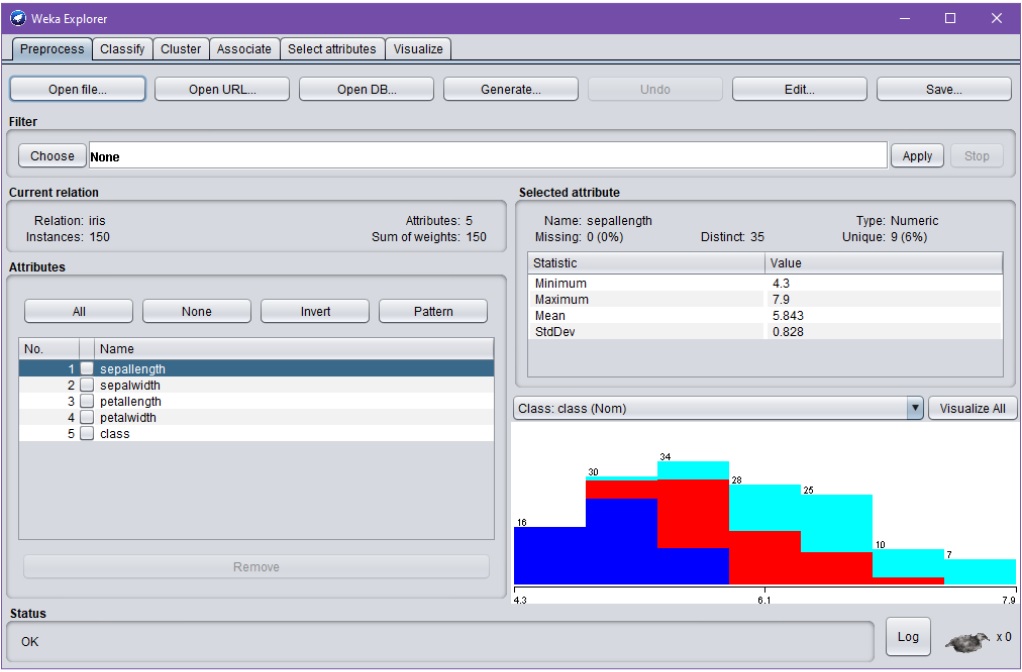
Esikäsittelyvaiheen (Preprocess) aikana on mahdollista esim. systemaattisesti muokata, tarkastella ja erittäin monipuolisesti valita/rajata attribuutteja varsinaiseen opetukseen ja luokitteluun, sekä tutkia attribuuttijakaumia ja näiden tunnuslukuja.
Visualisointi-välilehti (Visualize) havainnollistaa attribuutteja ja näiden välisiä suhteita:
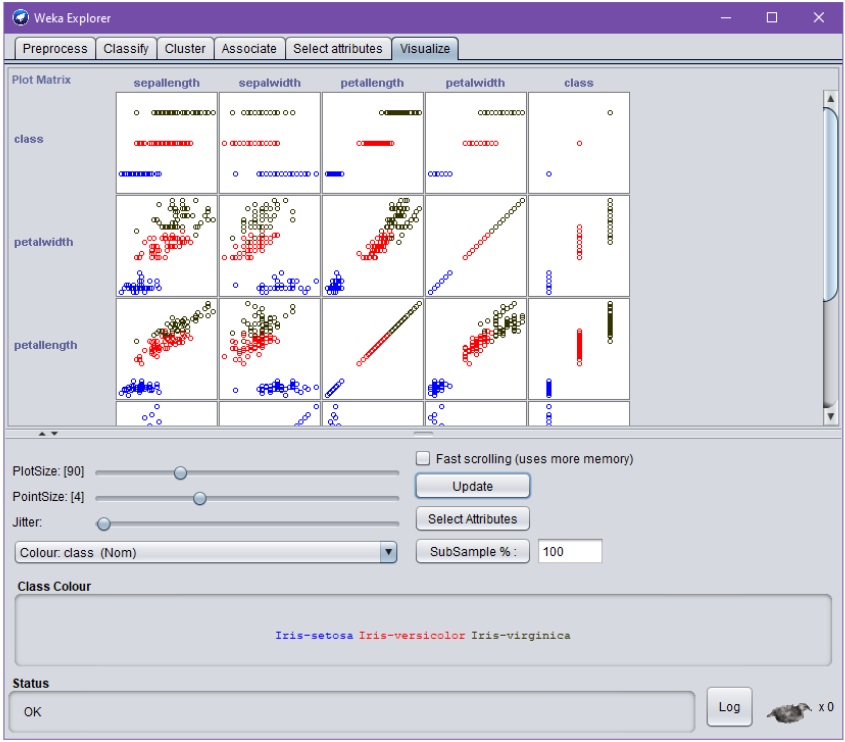
Yo. kuvioista huomataan tässä tapauksessa jo ennen koneoppimisen kokeiluita, että esim. attribuutit petalwidth ja petallength sopivat lähes sellaisenaan luokitteluun, ja että ne korreloivat keskenään.
Kuvioita klikkaamalla pääsee tutustumaan vielä tarkemmin eri attribuuttien arvoihin, tarvittaessa yksittäisten instanssien tai tässä ”datapisteiden” tarkkuudella.
Vaihe 5: Valitaan luokitteluvälilehti (Classify) ja siltä opetusalgoritmi (Choose) ja asetetaan algoritmin parametrit:
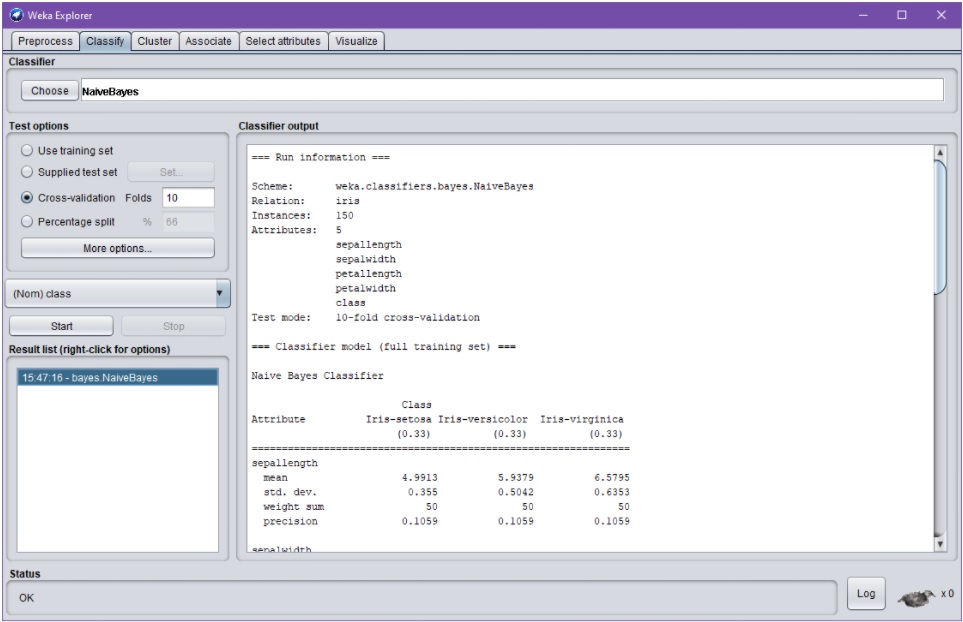
Seuraavassa on valittu Classifier-kentästä NaiveBayes-algoritmi:
![Weka Explorer –dialogin Classify-välilehti, jossa ladattuna iiris-aineisto. Välilehti tarjoaa mahdollisuuden koneoppimisen algoritmin valintaa (Classifier > Choose); nyt valittuna NaiveBayes-algoritmi. Dialogi sisältää myös ryhmät "Test options", "Classifier output" sekä "Result list". Ryhmän "Test options" puitteissa on nyt valitty "Cross-validation [with] Folds: 10" ja luokitteleva attribuutti "(Nom) class". Opetus- ja validointiajon käynnistys onnistuu Start-nappulalla.](https://blogs.tuni.fi/app/uploads/2021/05/dc6d4724-clf.jpg)
Algoritmista riippuen sille voidaan antaa useita erilaisia parametreja ja muita Wekan konfiguraatioasetuksia. Tämä tapahtuu klikkaamalla valkoisella pohjalla lukevaa, valitun algoritmin nimikenttää (tässä NaiveBayes):
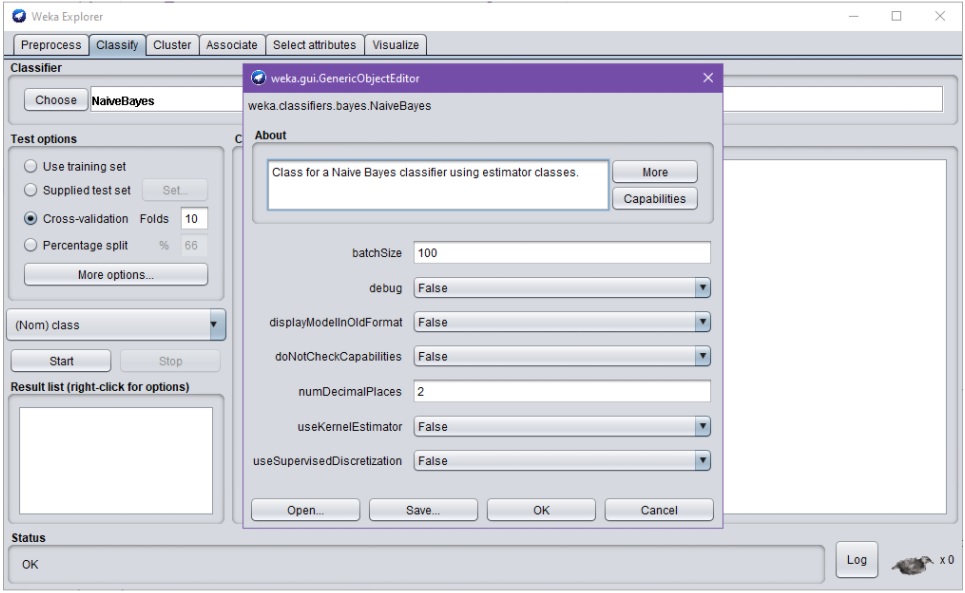
Klikkaamalla edelleen dialogin More-nappulaa, saadaan tarkempi ohje valitun algoritmin toiminnasta:

Capabilities-nappulan takaa löytyy puolestaan kuvaus algoritmin kyvykkyyksistä tai olettamuksista datan suhteen.
Ohjeiden ja niiden termien ymmärtäminen edellyttää yleensä perustietoja valitun algoritmin ja koneoppimisen toiminnasta.
On myös hyvä huomata, että esim. Naive Bayes -algoritmin käsite on varsin yleinen, mutta Weka-kirjaston nimenomaisen weka.classifiers.bayes.NaiveBayes -ohjelmistokomponentin toteutus varsin spesifinen. Siten esim. jonkin toisen työkalun tai kirjaston Naive Bayes –toteutus voi tarkkaan ottaen olla erilainen esim. parametrien ja opetusalgoritmin olettamusten osalta (esim. vaatimus nominaaliasteikollisista muuttujista), vaikka toki perustuukin samaan abstraktin Naive Bayes -algoritmin ideaan.
Aineiston mallinnus, esikäsittely ja opetusalgoritmien parametrien valinta ovat yleensä koneoppimisen ja siten myös Wekan käytön kaikkein hankalimpia tehtäviä. Ei esim. ole syytä olettaa, että Wekan ehdottamat parametrit toimisivat parhaiten. Toisaalta koneoppimisen perusalgoritmit ovat yleensä toteutukseltaan varsin koeteltuja ja siten melko virheettömiä: Jos opetettu malli ei toimi halutulla tavalla, kyse on lähes poikkeuksetta aineiston riittämättömyyden (tai tehtävän vaikeuden), datan valmistelun, algoritmin ja sen parametrien valinnan — tai yksinkertaisesti sovelluksen tai työkalujen käytön ymmärtämisen — ongelmista.
Opetusdatan ja algoritmien parametrien valinnan perustavoite on johtaa tai opettaa malli, joka intuitiivisesti sanottuna osaa yleistää oppimaansa. Hyvä malli osaa siten esim. paitsi luokitella opetusdatansa instansseja, osaa se myös luokitella validointi- ja testidatan instansseja. Erityisesti, monimutkaisten algoritmien mallien tapauksessa voi käydä niin, että malli ylioppii ”muistamaan ulkoa” opetusdatan (overfitting) — muttei sitten toimikaan validointidatan saati tuotantovaiheen testidatan kanssa.
Ylioppimista voidaan välttää opetusdatajoukkoa pienentämällä sekä sopivien parametrien valinnalla. Esimerkiksi päätöspuun tai neuroverkon solmujen lukumäärä vaikuttaa siihen, kuinka monimutkaisia oppimistuloksia (tai matemaattisia funktioita) niiden avulla voidaan mallintaa.
Kaikki oppimisalgoritmit eivät toimi (hyvin) kaikentyyppisillä (kuvailevilla) attribuuteilla. Sopivien attribuuttien laatu tulee tarkistaa algoritmien ohjeista (vrt. edelliset esimerkit) ja opetusmateriaalista (ks. esim. [8,9,10]). Usein kuvailevien attribuuttien tulisi olla numeerisia ja vähintään järjestysasteikollisia muuttujia. Joidenkin algoritmien tapauksessa attribuuttien arvot tulisi lisäksi vielä normalisoida, eli skaalata sopivasti.
Huomaa, että edellä luokittelevaksi attribuutiksi on nyt (automaattisesti) valittu nominaali- eli luokitteluasteikollinen [11] class-attribuutti. Tämä tarkoittaa sitä, että Weka käyttää aineiston kunkin datarivin muita attribuutteja havaintoyksikön kuvailuun ja yrittää esimerkkien perusteella rakentaa mallin, joka oppii ennustamaan viidennen class-attribuutin arvon NaiveBayes-algoritmin avulla.
Klassisen koneoppimisen käyttötapauksissa Naive Bayes –algoritmi tuottaa yleensä tulosten perustason, jonka perusteella tuloksia pyritään parantamaan. Luokitustuloksia on mahdollista parantaa eri algoritmeja kokeilemalla, sopivilla parametrien valinnoilla sekä keräämällä tai oivaltavasti esikäsittelemällä (lisää) aineistoa.
Vaihe 6: Suoritetaan varsinainen mallin opetus- ja validointi Start-nappulaa klikkaamalla. Validointi tehdään tyypillisesti esim. 10-ositteiseilla cross-validation toiminnolla (oletus).
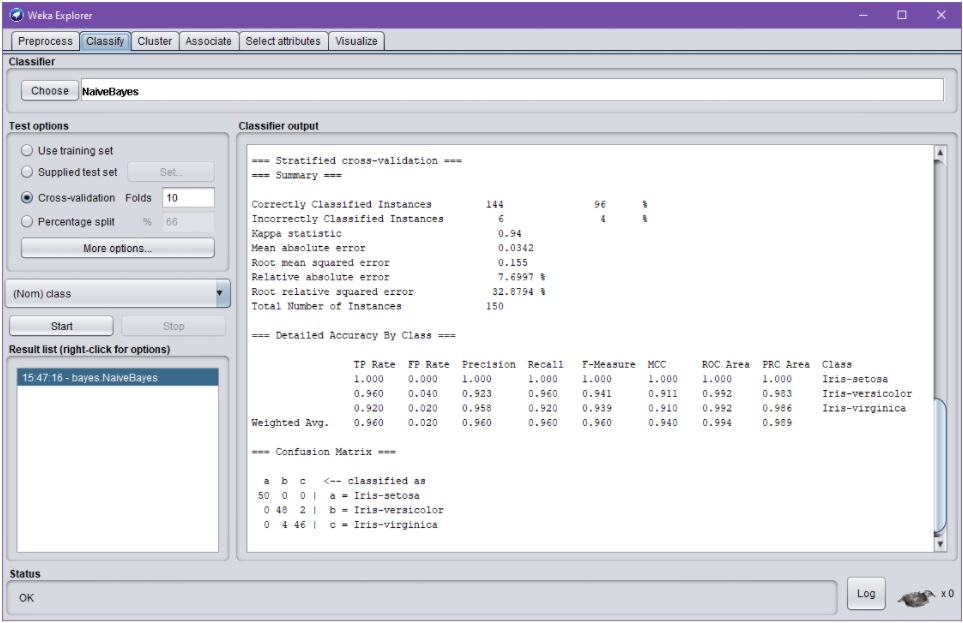
Suorituksen kesto määräytyy aineiston koon, algoritmivalintojen ja validointiprosessin mukaan. Ajon tuloksena saadaan tässä pienessä esimerkkitapauksessa lähes viiveettä tekstimuotoinen raportti, joka jää tulosikkunaan (Classifier output):
Raportista käy ilmi mm. opetus- ja testiaineiston koko ja laatu, aineistoa kuvaavia tunnuslukuja sekä validoinnin tiedot.
Tuloksen kannalta mielenkiintoisia tietoja ovat mm. luokitustarkkuus (tässä tapauksessa 96% oikein; yleensä 95% tai yli on ”erittäin hyvä” tarkkuus) ja muut laatumittarit sekä sekaannusmatriisi (confusion matrix). Sekaannusmatriisista näkee, minkälaisia virheitä opetettu malli tekee: Esimerkkiajossa malli antoi esim. kaksi kertaa luokitustuloksen Iris-virginica, kun oikea vastaus olisi ollut Iris-versicolor (sekaannusmatriisin rivi 0 48 2).
Ikävä kyllä, koneoppimisen kokeilut eivät yleensä tuota näin hyviä tuloksia, ainakaan ensiyrittämällä!
Nyt hyvään tulokseen päästään, koska valittu iiris-aineisto sisältää sellaisenaan huomattavan helposti tunnistettavaa säännönmukaisuutta — minkä toteaminen onnistuu helposti jo siis visualisoinneista ”katsomalla”, ilman koneoppimistakin (vrt. yllä olevat esimerkit). (Juuri intuitiivisuutensa ansiosta ko. aineistoa käytetään usein analytiikan ja koneoppimisen esimerkeissä, havainnollistamaan aihepiirin käsitteitä ja menetelmiä.)
Huomaa että paitsi tietenkin kohdesovelluksen laatukriteerit, myös esim. luokkien lukumäärä vaikuttaa tulosten arvioinnissa: Esimerkiksi 60% tarkkuus kaksiarvoisen luokittelevan attribuutin tapauksessa on monessa tapauksessa huono tulos: Syy on se, että jo arvaamalla aina sitä luokkaa jota aineistossa esiintyy eniten, pääsee aina vähintään 50% tarkkuuteen!
Validointitavasta riippuen, tuloksissa saattaa esiintyä satunnaisuutta. Yleisessä tapauksessa edellä annetulla parametreilla kaksi peräkkäistä ajoa saattaisivat siten antaa hieman poikkeavia tuloksia. Tosin Weka Explorerin tapauksessa Wekan pseudosatunnaislukujen generointi pyrkii oletuksena generoimaan aina samoja satunnaislukuja ja siten samoja validointituloksia, mikä tässä tapauksessa voi olla hieman harhaanjohtavaa.
Ideaalitapauksessa algoritmien ja näiden parametrien valinta ja kokeilut tehdään kehitysvaiheessa opetus- ja validointiodatan avulla — mutta lopullinen testaus sellaisella tuotannon testidatalla, jota ei ole lainkaan käytetty opetus- ja validointivaiheessa. Muussa tapauksessa voi käydä niin, että mallien valintaa ym. (tahattomasti) ylioptimoidaan juuri opetus- ja validointidatalle sopiviksi, tuloksena ei-toivottua ylioppimista.
Weka Exploreriin on graafisen käyttöliittymän avulla myös mahdollista ladata luokittelemattomia datarivejä (class-attribuutti arvossa ?), ja käyttää opetettua mallia niiden luokitteluun.
Raportit eri ajoista jäävät myös Result list –ikkunaan, jonka avulla on mahdollista vertailla erilaisia kokeiluita.
Validoinnin tuloksia ja mallien tuottamia luokittelutuloksia voidaan tutkia Wekassa myös tarkemmin, valitsemalla hiiren oikealla napilla Result-listan elementtejä. Esimerkiksi seuraava visualisointi havainnollistaa opetetun NaiveBayes-luokittelijan tekemiä virheitä (scatterplot-kuvion suorakaiteet):
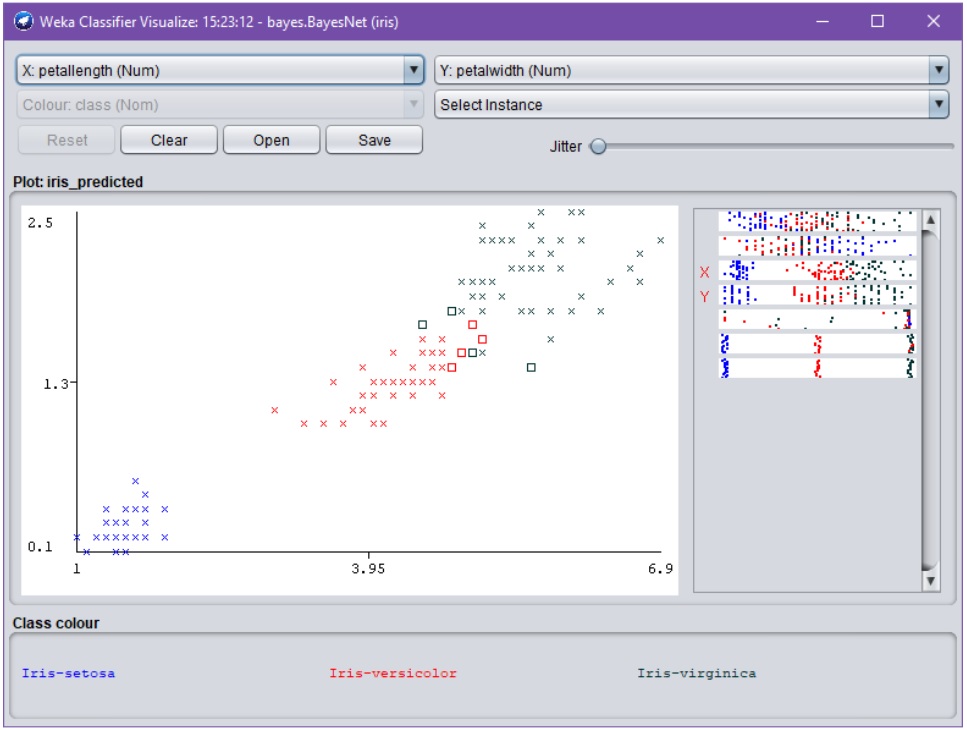
Yllä olevasta kuvasta huomataan, että suorakaiteiden osoittamat luokitteluvirheet tapahtuvat oletetusti ”luokittelurajoilla” (decision boundary). Huomaa visualisoinnin vastaavuus sekaannusmatriisin kanssa.
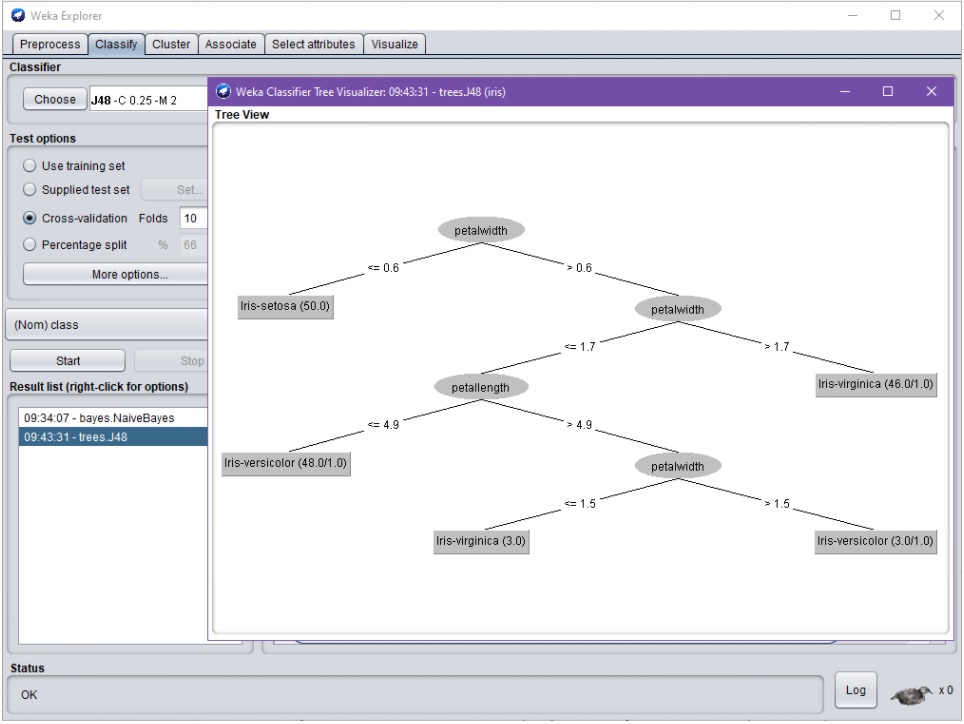
Tiettyjen algoritmien tapauksessa, on myös mahdollista visualisoida opetettuja malleja. Esimerkiksi toisen ajon ja tällä kertaa päätöspuuoppijan (decision tree) tapauksessa, voidaan tutkia opetettua (pientä) päätöspuuta:
![Weka Classifier Tree Visualizer –dialogi. Dialogissa esitetään testiajossa opetettu, yhdeksästä solmusta koostuva päätöspuu graafisessa muodossa siten, että puun juurisolmu on piirretty ylimmäisenä. Tuloksena on nyt saatu binääripuu, jonka juurisolmu sisältää oleellisesti testin "petalwidth<=0.6". Jos testin tulos on tosi, tuottaa puu luokittelutuloksen "Iris-setosa". Jos testi on taasen epätosi, jatketaan puun oikean haaran mukaisilla seuraavilla testeillä, missä seuraavana vuorossa on testi "petalWidth<=1.7". Puu sisältää tietoa myös solmujen "puhtaudesta" [purity].](https://blogs.tuni.fi/app/uploads/2021/05/6a387ad8-dt.jpg)
Päätöspuusta esim. huomataan, että tässä tapauksessa attribuutti petalwidth jakaa aineiston parhaiten. Tämä on intuitiivisesti odotettu tulos.
Useimmat koneoppimisen algoritmit toimivat kuitenkin mustan laatikon tavoin, eivätkä päätöspuiden tavoin tarjoa intuitiivista selitystä toiminnalleen (jonka esim. sovellusasiantuntija voisi tarkistaa). Tällöin niiden toimintaa voidaan arvioida vain tilastollisesti.
Esimerkiksi Naive Bayes –tyyppinen malli on pohjimmiltaan ”vain” oppimisalgoritmin tuottama joukko tiiviitä numeerisia taulukoita, joiden avulla luokitusalgoritmi laskee todennäköisimmän luokitustuloksen annettujen kuvailevien attribuuttien perusteella. Taulukot voisi tietenkin tallettaa tekstitiedostoon, mutta niiden tulkinta olisi algoritmin tarkkaa toimintaa ymmärtävällekin ihmiselle toivottoman hidasta ja aikavievää.
Vaihe 7: Mikäli halutaan tehdä kokeiluita klusterointiin, assosiatiivisten sääntöjen louhintaan tai attribuuttien valintaan liittyen, kokeillaan myös muita Weka-välilehtiä.
Vaihe 8: Mikäli tarpeen, valmiita malleja voidaan myös tallettaa tai eksportoida graafisesta Weka-ympäristöstä ulkoisiin tiedostoihin sekä edelleen ladata ja käyttää Weka-ohjelmointikirjaston avulla osana Java-pohjaisia ratkaisuita (so. ilman edellä esitettyjä graafisia Weka-sovelluksia). Tässä tulee huomioida GPL-lisenssin käyttö ja soveltaminen.
Huomaa, että vastaaviin tuloksiin on myös mahdollista päästä muilla koneoppimisen kirjastoilla, hyödyntäen vastaavien algoritmien (kaupallisia) toteutuksia, esikäsiteltyä dataa sekä sopivia parametreja.
4. Lopuksi
Tulosten hyväksyttävyyttä arvioitaessa kannattaa pitää mielessä, että koneoppimisen mallit toimivat pääsääntöisesti vain tietyllä tilastollisella tarkkuudella. Hyväkin ennuste- tai luokittelumalli voi esimerkiksi tuhannen ajon tapauksessa antaa keskimäärin yhdeksässä tapauksessa kymmenestä oikean tuloksen — mutta siten yhdessä tapauksessa kymmenestä (täysin) väärän.
Erityyppisiä virheitä sattuu siis väistämättä. Koneoppimisen virheiden vaikutusten minimointi kriittisissä sovelluksissa on siten tärkeää, aivan kuten ihmistenkin tekemien virheiden vaikutusten minimointi on.
Lähteitä
[1] Weka 3 – Data Mining with Open Source Machine Learning Software. Machine Learning Group at the University of Waikato. Saatavilla https://www.cs.waikato.ac.nz/ml/weka/index.html
[2] Primer – Wka Wiki. University of Waikato. Saatavilla https://waikato.github.io/weka-wiki/primer/
[3] Commercial applications – Wka Wiki. University of Waikato. Saatavilla https://waikato.github.io/weka-wiki/faqs/commercial_applications/
[4] Data Mining with Weka MOOC – Material. Department of Computer Science at the University of Waikato. Saatavilla https://www.cs.waikato.ac.nz/ml/weka/mooc/dataminingwithweka/
[5] Brownlee, J. (2019). A Tour of the Weka Machine Learning Workbench. Machine Learning Mastery Pty. Ltd. Saatavilla https://machinelearningmastery.com/tour-weka-machine-learning-workbench/
[6] Arff stable – Wka Wiki. University of Waikato. Saatavilla https://waikato.github.io/weka-wiki/formats_and_processing/arff_stable/
[7] Data Mining: Practical Machine Learning Tools and Techniques. Machine Learning Group at the University of Waikato. Saatavilla https://www.cs.waikato.ac.nz/~ml/weka/book.html
[8] Class NaiveBayes, Weka developer documentation. University of Waikato. Saatavilla https://weka.sourceforge.io/doc.dev/weka/classifiers/bayes/NaiveBayes.html
[9] weka-dev 3.9.5 API. Weka developer documentation. University of Waikato. Saatavilla https://weka.sourceforge.io/doc.dev/index.html?overview-summary.html
[10] Brownlee, J. (2019). How To Use Classification Machine Learning Algorithms in Weka. Machine Learning Mastery Pty. Ltd. Saatavilla https://machinelearningmastery.com/use-classification-machine-learning-algorithms-weka/
[11] Mittaaminen: Muuttujien ominaisuudet. Tietoarkisto. Saatavilla https://www.fsd.tuni.fi/menetelmaopetus/mittaaminen/ominaisuudet.html
[12] Iris flower data set. Wikipedia. Saatavilla https://en.wikipedia.org/wiki/Iris_flower_data_set
[13] Data Mining with Weka. Online Course. University of Waikato. Saatavilla https://www.futurelearn.com/courses/data-mining-with-weka

Kommentit