

Oletko koskaan tehnyt jotain tehtävää, jonka tiedät tehneesi jo aiemmin? Viime kerrasta on jo kulunut ehkä sen verran aikaa, ettei aivan kaikkia asiaan liittyviä vaiheita enää muista tarkasti. Tehtävän eri vaiheisiin liittyvät työkalut ja muu oheismateriaali ovat myös hieman levällään, joten tehtävää ei tuosta vain voi aloittaa. Sitten kun lopulta pääsee vauhtiin, huomaa, ettei aikaisempia tuloksia voikaan käyttää sellaisenaan, joten tehtävä täytyy suorittaa alusta alkaen uudelleen.
Tällaisiin tuntemuksiin olen törmännyt useita kertoja tieto- ja ohjelmistotekniikkaan liittyvien pulmien kanssa. Tehtävä voi olla sinällään yksinkertainen, kuten vaikkapa tiedoston sisällön päivitys ja uuden raportin laatiminen päivitetyn sisällön perusteella. Yksinkertaisuudesta huolimatta tehtävän automatisointi voi olla turhan työlästä tai hankalaa. Toisaalta, automatisoinnin kaikkien vaiheiden ylläpitäminen voi viedä enemmän resursseja kuin oli kaavailtu. Tiettyyn tarkoitukseen toteutetun ratkaisun vaiheista osa saattaisi olla käyttökelpoisia yleisluontoisissa ratkaisuissa, mutta niiden hallinta ja hyödyntäminen uudelleenkäytettävinä komponentteina vaatii taas lisää työtä. Siten tehtävää suoritettaessa joudutaan tasapainoilemaan erilaisten laatuparametrien, kuten yleiskäyttöisyyden, yhteensopivuuden, ja uudelleenkäytettävyyden kanssa.
Mitä asiasta tiedettiin?
Tästä päästäänkin lähemmäs tutkimusaluetta, eli tiedonkäsittelyä ohjelmistoissa. Tietoa ja dataa tuotetaan jatkuvasti lisää kasvavalla tahdilla. Lisäksi tiedon monimuotoisuus lisääntyy, kun tieto koostuu entistä enemmän jäsentelemättömästä datasta. Tämä aiheuttaa haasteita ohjelmistokehityksessä muun muassa tietointensiivisien sovellusten datan prosessoinnissa.
Samalla on havaittu tarve datan ja datalähteiden loogiselle ja systemaattiselle hallinnalle. Tämä on edellytys sille, että ohjelmistoilla tuotettua tietoa voitaisiin käsitellä entistä tehokkaammin. Suuren ”big datan” looginen ja systemaattinen hallinnointi muodostaakin — fyysisten rajoitteiden ohella — merkittävän haasteen tulevaisuuden informaatiojärjestelmissä.
Ohjelmistokehityksen normeissa on tiedostettu ohjelmiston kohteena olevan tiedon laatuparametreja, mutta ohjelmistojen laadusta puhuttaessa on perinteisesti keskitytty ohjelmakoodin mittaamiseen. Yhtäkaikki, tarvitaan resursseja, jotta voidaan varmistaa riittävä laatu niin ohjelmakoodin kuin käytetyn datan suhteen.
Kirjallisuuden perusteella vaikuttaa kuitenkin siltä, ettei yleiskäyttöiseen dataprosessointiin ja systemaattiseen hallintaan soveltuvaa ohjelmistoratkaisua ollut olemassa. Tutkimuksen tavoitteeksi muodostuikin etsiä dataprosessoinnin mahdollistava yleiskäyttöinen malli.
Perinteinen keittiönallas kuvaa tiedonkäsittelymallia
Millä tavalla tietoa voitaisiin siis käsitellä ohjelmistoissa? Tutkimuksen edetessä keksin käyttää tiedon ja datan analogiana virtaava vettä. Tämä ei välttämättä ollut aivan uniikki ajatus, mutta sen pohjalta kehittämäni Allasmalli sitävastoin oli. Mallin esikuvana toimi tuikitavallinen keittiöallas. Sen kuvaaviksi pääkomponenteiksi valikoituivat 1) hana, 2) virtaava vesi, 3) allas, 4) siivilä, ja 5) viemäriputkisto.
Jokaisella komponentilla on oma tehtävänsä niin esikuvassaan kuin abstraktoidussa mallissa. Hana esittää lähtökohtaa, josta data päästetään määritetyn protokollan mukaisesti järjestelmään. Virtaava vesi on kuvaus tietolähteestä saapuvista tietovirroista. Allas toimii tietovirran datapisteiden, eli veden, säilytys- ja katselmointipaikkana. Siivilä taas osaa poimia määrityksien mukaisia tietovirtoja. Putkiston tehtävä on kuljettaa käsiteltyä tietoa eteenpäin.
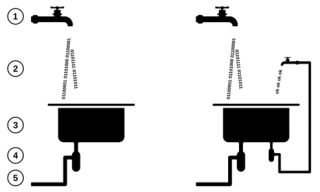
Kuvan 1. oikeanpuoleisessa altaassa näkyy yksinkertaisena esimerkkinä se, miten allasmalliin lisätään uusia tiedonkäsittelysyklejä. Tässä uusi siivilä on valinnut toisen alkuperäisestä hanasta tulevan tietovirran, ja muuttanut tietovirran binäärimuotoiset datapisteet tekstimuotoisiksi datapisteiksi. Uusi tekstimuotoinen datavirta päästetään takaisin järjestelmään oikeanpuoleisesta pikkuhanasta. Näitä syklejä on mahdollista jatkaa erilaisten toimintojen ja valintasääntöjen kanssa kunnes haluttuun lopputulokseen on päästy.
Mallin yleisluontoisuudesta johtuen se ilmentyy erilaisena valitusta näkökulmasta riippuen.
• Mallina se edustaa käsitteellistä ideaa liukuhihnoitetusta tiedonkäsittelystä. Mallin mukainen toiminta voidaan ottaa käyttöön sovelluksissa esimerkiksi ohjelmistokirjaston tai -kehyksen muodossa.
• Suunnittelumallina se edustaa yleiskäyttöistä ja uudelleenkäytettävää malliratkaisua tiedonkäsittelyn ja -hallinnan haasteisiin.
• Ohjelmistokehyksenä se voi tarjota ohjelmistoille käyttövalmiin ja edelleen jatkokehitettävän erilliskomponentin tiedonkäsittelyn perustarpeisiin.
• Ohjelmistoarkkitehtuurina se määrittää yhtenäisen järjestelmäyksikön erilaisten ongelmien ratkaisuun. Tämän väitöstyön puitteissa keskitytään tehokkaaseen datalähteiden käsittelyyn ja systemaattiseen hallintaan.
Miksi loin vesialtaisiin perustuvan viemärimallin?
Mikä ominaisuus tekee työstä parasta sitten siivutetun leivän? Asiaa lisää tutkiessa kävi ilmeiseksi, että allasmallin tietovirtojen käsittelyssä olevat viisi perusosaa on sovitettavissa tyypillisen informaatiojärjestelmän päätason tehtäviin. Nämä päätason tehtävät olivat (tiedon): hankinta, tallennus, tunnistaminen ja suodatus, käsittely, sekä visualisointi.
Malli tarjoaakin rakenteellisen, ennalta määritellyn tavan toimia. Malliin suunniteltu yleiskäyttöisyys mahdollistaa sovelluskohtaisen varioinnin eli muuntelun. Ohjelmiston datankäsittely-yksikkö voi siis tarpeen mukaan erikoistua erilaisiin tehtäviin. Muuntelupisteet itsessään voivat hyödyntää uudelleenkäytettäviä tiedonkäsittelykomponentteja. Nämä seikat osaltaan ohjaajat tekijäänsä toimimaan hyvien käytänteiden mukaisesti.
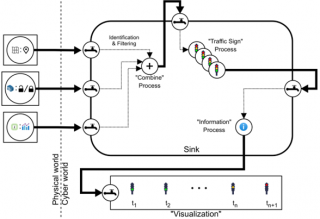
Kuvassa 2 näkyy esimerkki, jossa kolmea erityyppistä tietolähdettä yhdistellään toisiinsa ”yhdistely”-muuntelupisteen prosessin avulla. Yhdistetty data kulkee uuden syklin, ja päätyy sarjaan joka kuvaa useammasta ”liikennevalo”-muuntelupisteestä koostuvaa prosessia. Tämän prosessin tuotos ohjataan vielä ”informaatio”-prosessiin josta se suuntaa tiensä toiseen allasmallikelpoiseen visualisointijärjestelmään.
Mallin mukaista ratkaisua kokeiltiin alussa kuvailemassani käyttötilanteessa prototyyppijärjestelmän muodossa. Tätä varten kehitettiin myös Manageable Data Sources -niminen ohjelmistokomponenttikehys. Käytännössä protyyppijärjestelmällä suoritettiin julkaisussa VI kerätyn maantien tärinämittausdatan laskentaa ja raportointia. Lähtömateriaalina käytetty ”tärinädata” oli taulukkomuotoista, ja sisälsi enimmäkseen numeraalista tietoa lähes puoli miljoonaa riviä. Mittausdataa oli ajatus täydentää toisessa käyttötapauksessa ulkoisesta lähteestä noudetulla säädatalla, mutta tätä ei lopulta toteutettu rajallisen työaikamäärän vuoksi. Kolmannessa käyttötapauksessa kuvattiin edelleen edistyneempi versio mallin laajennettavuudesta ja yleiskäyttöisyydestä. Tätä varten oli valittu esimerkki, jossa on erilaisemmat lähtödatat, myös tietolähteiden lukumäärä oli kasvatettu.
Ohjelmistojen sekä datan uudelleenkäytettävyys ja laatu paranee
Väitöskirjassani kehittämäni yleiskäyttöinen tiedonkäsittelymalli nitoo yhteen ohjelmistokehityksen ja datan hallinnoinnin hyödyntäen ohjelmistotekniikan tapoja käyttää suunnittelumalleja. Se tarjoaa rakenteellisesti uuden menetelmän toistuvaisesta tietojenkäsittelystä ohjelmistoissa. Täten ohjelmistokehitys selkeytyy ja tulee ymmärrettävämmäksi. Helpommin hallinnoitavan datan laadukkaalla uudelleenkäytöllä voidaan saavuttaa etuja esimerkiksi laskentaresurssien käytössä.
Palatakseni alkuun, tehdyn taustatutkimuksen, prototyyppijärjestelmistä saadun empirian, sekä saatujen tulosten perusteella esitettyä mallia on mahdollista hyödyntää datankäsittelyyn liittyvissä käyttötapauksissa. Täten väitän, että kehitetyn tiedonkäsittelymallin avulla voidaan parantaa sekä ohjelmistojen että datan uudelleenkäytettävyyttä ja laatua.

Pekka Sillberg
tekniikan tohtori



Kommentit